一、前言
EF的CodeFirst是个好东西,让我们完全不用考虑数据库端(注意,这里并不是说不需要对数据库知识进行了解),一切工作都可以通过代码来完成。EF是ORM,已经把数据访问操作封装得很好了,可以直接在业务层中使用,那我们为什么还要对其进行那么多封装呢?在我看来,封装至少能带来如下的好处:
1.把EF的相关对象封装在数据访问层中,解除了业务层对EF的依赖。
2.统一EF的数据操作,以保证业务层使用相同的代码规范。
3.隐藏EF的敏感配置,降低EF的使用难度。
这里就引入一个问题,应该怎样来进行EF的封装呢,既要保证使用的统一与方便性,又要保持EF的灵便性,否则,封装将变成给业务层设置障碍。下面,主要针对数据查询进对可能出现的误用情况进行分析。
二、查询问题分析
(一) 数据查询应该在哪做在EF中,面向对象的数据查询主要提供了两种方式:
1.TEntity DbSet<TEntity >.Find(params object[] keyValues):针对主键设计的通过主键查找单个实体,会先在EF的本地数据集Local中进行查询,如果没有,再去数据库中查询。
2.IQueryable<T >、IEnumerable<T >类型的所有数据查询的扩展方法(由于DbSet<T >继承于IQueryable<T >与IEnumerable<T >),如SingleOrDefault,FirstOrDefault,Where等。其中IQueryable<T >的扩展方法会先收集需求,到最后一步再生成相应的SQL语句进行数据查询;而IEnumerable<T >的扩展方法则是在查询的第一步就生成相应的SQL语句获取数据到内存中,后面的操作都是以内存中的数据为基础进行操作的。
以上两种方式为EF的数据查询提供了极大的自由度,这个自由度是我们在封装的时候需要保持的。但是,在阅读不少人(其中不乏工作了几年的)对EF的封装,设计统一的数据操作接口Repository中关于数据查询的操作中,通常会犯如下几种失误:
1.设计了很多GetByName,GetByXX,GetByXXX的操作,这些操作通常并不是所有实体都会用到,只是部分实体的部分业务用到,或者是“估计会用到”。
2.定义了按条件查询的SingleOrDefault,FirstOrDefault,Count,GetByPredicate(predicate)等方法,但是对于条件predicate的类型是使用Expression<Func<TEntity, boo > >还是Func<TEntity, bool >很纠结,最后干脆两个都设计,相当于把IQueryable<T >,IEnumerable<T >的方法再过一遍。
3.定义了获取全部数据的GetAll()方法,但却使用了IEnumerable<TEntity >类型的返回值,明白的同学都知道,这相当于把整个表的数据都加载到内存中,问题很严重,设计者却不知道。
诸如此类,各种奇葩的查询操作层出不穷,这些操作或者破坏了EF数据查询原有的灵活性,或者画蛇添足。
其实,这么多失误的原因只有一个,设计者忘记了EF是ORM,把EF当作ado.net来使用了。只要记着EF是ORM,以上这些功能已经实现了,就不要去重复实现了。那么以上的问题就非常好解决了,只要:
在数据操作Repository接口中把EF的DbSet<TEntity >开放成一个只读的IQueryable<TEntity >类型的属性提供给业务层作为数据查询的数据源就可以了。这个数据源是只读的,并且类型是IQueryable<T >,就保证了它只能作为数据查询的数据源,而不像开放了DbSet<T >类型那样可以在业务层中调用EF的内部方法进行增、删、改等操作。另外IQueryable<T >类型保持了EF原有的查询自由性与灵活性,简单明了。这个数据集还可以传递到业务层的各个层次,以实现在哪需要数据就在哪查的灵活性。
(二) 循环中的查询陷阱EF的导航属性是延迟加载的,延迟加载的优点就是不用到不加载,一次只加载必要的数据,这减少了每次加载的数据量,但缺点也不言自明:极大的增加了数据库连接的次数,比如如下这么个简单的需求:
输出每个用户拥有的角色数量根据这个需求,很容易就写出了如下的代码:

遍历所有用户信息,输出每个用户信息中角色(导航属性)的数量。
上面这段代码逻辑很清晰,看似没有什么问题。我们来分析一下代码的执行过程:
1.132行,从IOC容器中获取用户仓储接口的实例,这没什么问题。
2.133行,取出所有用户信息(memberRepository.Entities),执行SQL如下:
SELECT
[Extent1].[Id] AS [Id],
[Extent1].[UserName] AS [UserName],
[Extent1].[Password] AS [Password],
[Extent1].[NickName] AS [NickName],
[Extent1].[Email] AS [Email],
[Extent1].[IsDeleted] AS [IsDeleted],
[Extent1].[AddDate] AS [AddDate],
[Extent1].[Timestamp] AS [Timestamp],
[Extent2].[Id] AS [Id1]
FROM [dbo].[Members] AS [Extent1]
LEFT OUTER JOIN [dbo].[MemberExtends] AS [Extent2] ON [Extent1].[Id] = [Extent2].[Member_Id]
虽然EF生成的SQL有些复杂,但还是没什么问题
3.136行,就开始有问题了,每次循环都会连接一次数据库,执行一次如下查询(最后一个1是用户编号):
exec sp_executesql N'SELECT
[Extent2].[Id] AS [Id],
[Extent2].[Name] AS [Name],
[Extent2].[Description] AS [Description],
[Extent2].[RoleTypeNum] AS [RoleTypeNum],
[Extent2].[IsDeleted] AS [IsDeleted],
[Extent2].[AddDate] AS [AddDate],
[Extent2].[Timestamp] AS [Timestamp]
FROM [dbo].[RoleMembers] AS [Extent1]
INNER JOIN [dbo].[Roles] AS [Extent2] ON [Extent1].[Role_Id] = [Extent2].[Id]
WHERE [Extent1].[Member_Id] = @EntityKeyValue1',N'@EntityKeyValue1 int',@EntityKeyValue1=1
试想,如果有100个用户,就要连接100次数据库,这么一个简单的需求,连接了101次数据库,还不得让数据库疯掉了。
当然,有同学可以要说,这里用了延迟加载才会多了很多连接数据库的次数,你可以立即加载啊,把Role角色一次性加载进来。好吧,我们来看看立即加载:

143行,在取所有用户信息的时候使用Include方法把与用户关联的所有角色信息也一并查询出来了,这样在循环遍历的时候就不会再连接数据库去查询角色信息了。但是如果看到执行的SQL语句,估计你想死的心情都有了。执行的查询如下:
SELECT
[Project1].[Id] AS [Id],
[Project1].[UserName] AS [UserName],
[Project1].[Password] AS [Password],
[Project1].[NickName] AS [NickName],
[Project1].[Email] AS [Email],
[Project1].[IsDeleted] AS [IsDeleted],
[Project1].[AddDate] AS [AddDate],
[Project1].[Timestamp] AS [Timestamp],
[Project1].[Id1] AS [Id1],
[Project1].[C1] AS [C1],
[Project1].[Id2] AS [Id2],
[Project1].[Name] AS [Name],
[Project1].[Description] AS [Description],
[Project1].[RoleTypeNum] AS [RoleTypeNum],
[Project1].[IsDeleted1] AS [IsDeleted1],
[Project1].[AddDate1] AS [AddDate1],
[Project1].[Timestamp1] AS [Timestamp1]
FROM ( SELECT
[Extent1].[Id] AS [Id],
[Extent1].[UserName] AS [UserName],
[Extent1].[Password] AS [Password],
[Extent1].[NickName] AS [NickName],
[Extent1].[Email] AS [Email],
[Extent1].[IsDeleted] AS [IsDeleted],
[Extent1].[AddDate] AS [AddDate],
[Extent1].[Timestamp] AS [Timestamp],
[Extent2].[Id] AS [Id1],
[Join2].[Id] AS [Id2],
[Join2].[Name] AS [Name],
[Join2].[Description] AS [Description],
[Join2].[RoleTypeNum] AS [RoleTypeNum],
[Join2].[IsDeleted] AS [IsDeleted1],
[Join2].[AddDate] AS [AddDate1],
[Join2].[Timestamp] AS [Timestamp1],
CASE WHEN ([Join2].[Member_Id] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1]
FROM [dbo].[Members] AS [Extent1]
LEFT OUTER JOIN [dbo].[MemberExtends] AS [Extent2] ON [Extent1].[Id] = [Extent2].[Member_Id]
LEFT OUTER JOIN (SELECT [Extent3].[Member_Id] AS [Member_Id], [Extent4].[Id] AS [Id], [Extent4].[Name] AS [Name], [Extent4].[Description] AS [Description], [Extent4].[RoleTypeNum] AS [RoleTypeNum], [Extent4].[IsDeleted] AS [IsDeleted], [Extent4].[AddDate] AS [AddDate], [Extent4].[Timestamp] AS [Timestamp]
FROM [dbo].[RoleMembers] AS [Extent3]
INNER JOIN [dbo].[Roles] AS [Extent4] ON [Extent4].[Id] = [Extent3].[Role_Id] ) AS [Join2] ON [Extent1].[Id] = [Join2].[Member_Id]
) AS [Project1]
ORDER BY [Project1].[Id] ASC, [Project1].[Id1] ASC, [Project1].[C1] ASC
(三) 导航属性的查询陷阱我们再来回顾一下导航属性的长相(以用户信息中的角色信息为例):

可以看到,集合类的导航属性是一个ICollection<T >类型的集合,其实现类可以是通常使用List<T >或者HashSet<T >。用了ICollection<T >,就限定了集合类的导航属性是一个内存集合,只要用到这个导航属性,就必须把集合中的所有数据都加载到内存中,才能进行后续操作。比如上面的例子中,我们的需求只是想知道用户拥有角色的数量,原意只是要执行一下SQL的Count语句即可,却想不到EF是把这个集合加载到内存中(上面的语句,是把当前用户的所有角色信息查询出来),再在内存中进行计数,这无形中是一个很大的资源浪费。比如在一个商城系统中,我们想了解一种商品的销量(product.Orders.Count),那就可能把几万条订单信息都加载到内存中,再进行计数,这将是灾难性的资源消耗。
读到这里,是不是对EF非常失望?
三、查询应该怎么设计
上面的问题,在项目的开发阶段,根本不是问题,因为软件照样能跑得起来,而且跑得好好的。但是等网站上线的时候,用户量上来的时候,这些性能杀手就暴露无遗了。是问题,总要想办法解决的。
下面就来说说我的解决方案,至于方案靠谱不靠谱,读者自行判断。
(一) 查询数据集设计在前面的设计中,实体的数据仓储接口已经向上层暴露了一个IQueryable<TEntity >的接口了,为什么暴露这个接口,上面也说了很多了。下面,以账户模块为例,我们就来看看怎样把这个查询数据集往上传递。
首先,不要忘了,我们的项目结构是这样的:
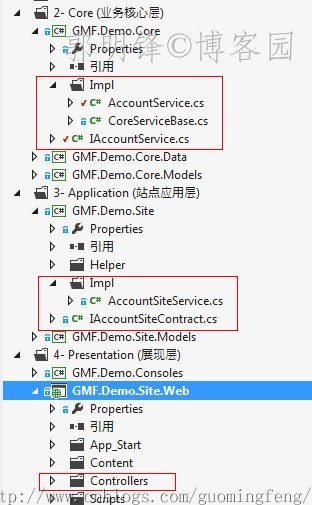
1.对注入的Repository接口进行保护
在核心业务实现类(AccountService)中,我们进行了各个相关实体的Repository接口的注入
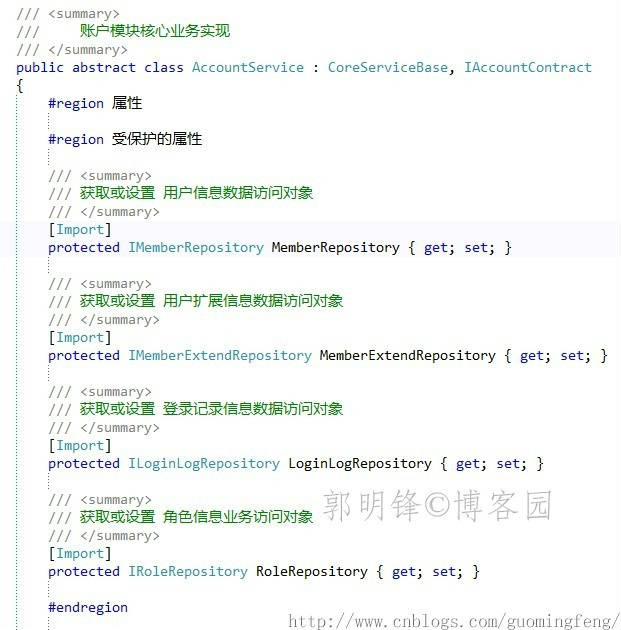
这里要注意,实体的Repository接口只能在业务层中使用,以防止开发者在展现层中调用增、删、改等数据操作以实现业务,而不是在业务层中进行业务实现。因而,注入的实体的Repository接口属性可访问性要修改为 protected。
2.开放查询数据集供展现层使用
业务层中的Repository接口都设置为 protected 了,那么在展现层无法访问 IEntityRepository.Entities 数据集了,怎样实现展现层的数据的查询呢,很简单,只要在业务接口中把 IEntityRepository.Entities 数据集 再包装成一个IQueryable<T >的查询数据集开发出去,就可以了。
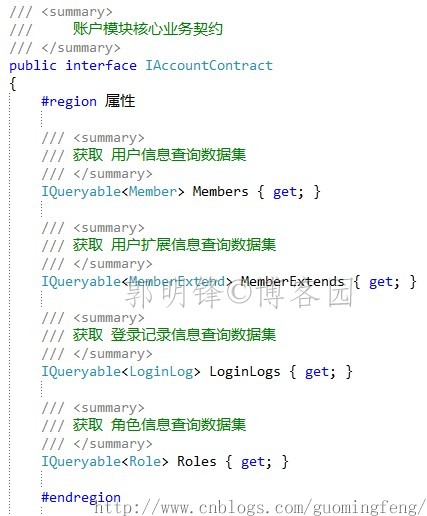
3.在业务实现类中进行 IEntityRepository.Entities 数据集的包装:
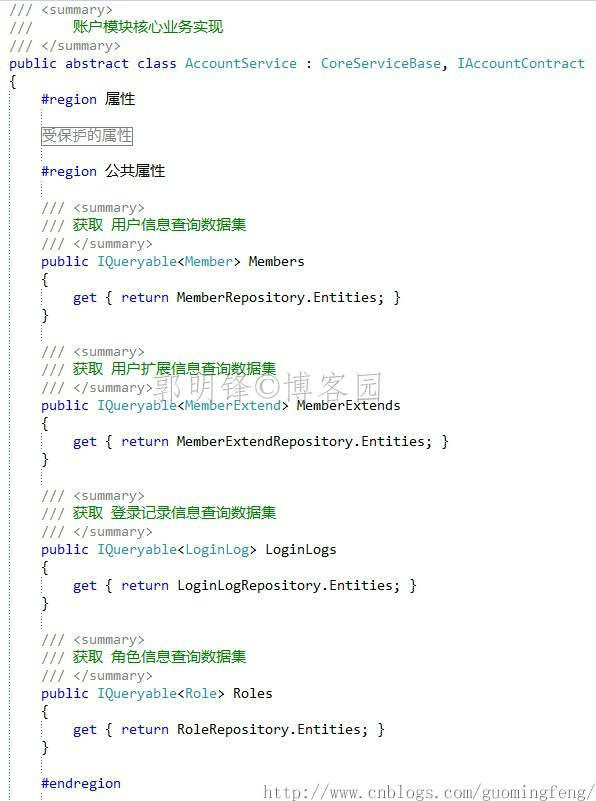
经过这样的封装,在业务层中,我们可以使用 IEntityRepository.Entities 数据集 进行数据查询,在展现层中使用业务契约中开放的数据集进行查询。由于开发的数据集仍是IQueryable<T >类型,对EF的查询自由度没有损耗。
(二) 查询陷阱的应对方案对于前面提到的EF的查询陷阱,我提出的解决方案就是
通过IQueryable<T >的 Select(selector) 扩展方法来按需查询。首先分析好当前业务中需要什么数据,要什么取什么,最后的数据用匿名对象装载。
比如前面提到的 输出用户拥有的角色数量 这个需求,实现方案如下:

以上代码执行的查询语句如下:
SELECT
[Extent1].[Id] AS [Id],
(SELECT
COUNT(1) AS [A1]
FROM [dbo].[RoleMembers] AS [Extent2]
WHERE [Extent1].[Id] = [Extent2].[Member_Id]) AS [C1]
FROM [dbo].[Members] AS [Extent1]
相当简洁,这才是我们需要的效果。
(三) 匿名对象方案与实体对象方案对比匿名对象的方案虽然达到了我们想要的效果,但对比实体对象方案,又有什么不同呢,下面我们来对比一下:
1.数据传递性、复用性:
-匿名对象:基本上属于一次性数据,无法整体传递,无法复用。
+实体对象:传递性,复用性良好。
2.对重构、方法提取的支持:
-匿名对象:由于数据无法传递,写出的代码很难进行重构,我就普写过几百行代码而无法提取子方法重构的方法。
+实体对象:数据对代码重构、方法提取支持良好。
3.对缓存命中率的影响:
-匿名对象:数据与具体的业务场景(参数、条件等)密切关联,缓存命中率可能会较低。
+实体对象:数据易复用,缓存命中率可能会较高。
4.不同层次的数据模型自动映射转换(AutoMapper等)
-匿名对象:属性不定,类型不定,难以转换。
+实体对象:轻松实现映射转换。
5.数据利用率:
+匿名对象:数据按需获取,利用率高,基本无浪费。
-实体对象:数据都是整体取出,利用率低,浪费大。
6.程序性能影响:
+匿名对象:容易写出运行高效的代码,性能良好。
-实体对象:容易写出性能低下的代码。
通过上面的对比,希望能对方案的选择提供一些参考,至于如何取舍,最终选择什么方案,只能自己根据业务的特点来权衡了,合适用哪个就用哪个。
四、需求实现
前面已经说过不少次了,这里在明确的提一次,在这个架构设计中,如果现有查询方法不能满足业务需求,需要添加一个相应的查询功能,你不需要到数据层去进行操作,你只需要:
扩展IQueryable<T >,给IQueryable<T >添加一个扩展方法。
(一) 按属性名称排序查询离不开分页查询,分页查询之前通常会先排序,再查出指定页的单页数据,先来说说按属性排序的问题吧。
排序可以使用IQueryable<T >的OrderBy、OrderByDescending两个扩展方法来进行,例如:
source.OrderBy(m = > m.AddDate).ThenByDescending(m = > m.IsDeleted);
这是系统提供的排序方法,但只支持 Expression<Func<TSource, TKey > > keySelector 类型的参数,而我们在点击表格的表头的时候,通常获取到的是实体的属性名称的字符串,所以我们还需要扩展一个支持属性名称的排序方法。
首先,定义一个类来封装排序条件,排序条件通常包括属性名称与排序方向:
namespace GMF.Component.Tools
{
/// <summary >
/// 属性排序条件信息类
/// </summary >
public class PropertySortCondition
{
/// <summary >
/// 构造一个指定属性名称的升序排序的排序条件
/// </summary >
/// <param name="propertyName" >排序属性名称</param >
public PropertySortCondition(string propertyName)
: this(propertyName, ListSortDirection.Ascending) { }
/// <summary >
/// 构造一个排序属性名称和排序方式的排序条件
/// </summary >
/// <param name="propertyName" >排序属性名称</param >
/// <param name="listSortDirection" >排序方式</param >
public PropertySortCondition(string propertyName, ListSortDirection listSortDirection)
{
PropertyName = propertyName;
ListSortDirection = listSortDirection;
}
/// <summary >
/// 获取或设置 排序属性名称
/// </summary >
public string PropertyName { get; set; }
/// <summary >
/// 获取或设置 排序方向
/// </summary >
public ListSortDirection ListSortDirection { get; set; }
}
}
其次,我们接收的是排序条件是属性名称的字符串,实际还是要调用系统提供的Expression<Func<TSource, TKey > > keySelector类型参数的排序方法进行排序。所以我们还需要一个把字符串条件转换为排序表达式,并调用系统的排序方法。
private static class QueryableHelper<T >
{
// ReSharper disable StaticFieldInGenericType
private static readonly ConcurrentDictionary<string, LambdaExpression > Cache = new ConcurrentDictionary<string, LambdaExpression >();
internal static IOrderedQueryable<T > OrderBy(IQueryable<T > source, string propertyName, ListSortDirection sortDirection)
{
dynamic keySelector = GetLambdaExpression(propertyName);
return sortDirection == ListSortDirection.Ascending
? Queryable.OrderBy(source, keySelector)
: Queryable.OrderByDescending(source, keySelector);
}
internal static IOrderedQueryable<T > ThenBy(IOrderedQueryable<T > source, string propertyName, ListSortDirection sortDirection)
{
dynamic keySelector = GetLambdaExpression(propertyName);
return sortDirection == ListSortDirection.Ascending
? Queryable.ThenBy(source, keySelector)
: Queryable.ThenByDescending(source, keySelector);
}
private static LambdaExpression GetLambdaExpression(string propertyName)
{
if (Cache.ContainsKey(propertyName))
{
return Cache[propertyName];
}
ParameterExpression param = Expression.Parameter(typeof (T));
MemberExpression body = Expression.Property(param, propertyName);
LambdaExpression keySelector = Expression.Lambda(body, param);
Cache[propertyName] = keySelector;
return keySelector;
}
}
到此,有了前面的准备,属性名称的排序就非常好写了。为了使用方便,应该做成IQueryable<T >的扩展方法:
/// <summary >
/// 把IQueryable[T]集合按指定属性与排序方式进行排序
/// </summary >
/// <param name="source" >要排序的数据集</param >
/// <param name="propertyName" >排序属性名</param >
/// <param name="sortDirection" >排序方向</param >
/// <typeparam name="T" >动态类型</typeparam >
/// <returns >排序后的数据集</returns >
public static IOrderedQueryable<T > OrderBy<T >(this IQueryable<T > source, string propertyName,
ListSortDirection sortDirection = ListSortDirection.Ascending)
{
PublicHelper.CheckArgument(propertyName, "propertyName");
return QueryableHelper<T >.OrderBy(source, propertyName, sortDirection);
}
/// <summary >
/// 把IQueryable[T]集合按指定属性排序条件进行排序
/// </summary >
/// <typeparam name="T" >动态类型</typeparam >
/// <param name="source" >要排序的数据集</param >
/// <param name="sortCondition" >列表属性排序条件</param >
/// <returns ></returns >
public static IOrderedQueryable<T > OrderBy<T >(this IQueryable<T > source, PropertySortCondition sortCondition)
{
PublicHelper.CheckArgument(sortCondition, "sortCondition");
return source.OrderBy(sortCondition.PropertyName, sortCondition.ListSortDirection);
}
/// <summary >
/// 把IOrderedQueryable[T]集合继续按指定属性排序方式进行排序
/// </summary >
/// <typeparam name="T" >动态类型</typeparam >
/// <param name="source" >要排序的数据集</param >
/// <param name="propertyName" >排序属性名</param >
/// <param name="sortDirection" >排序方向</param >
/// <returns ></returns >
public static IOrderedQueryable<T > ThenBy<T >(this IOrderedQueryable<T > source, string propertyName,
ListSortDirection sortDirection = ListSortDirection.Ascending)
{
PublicHelper.CheckArgument(propertyName, "propertyName");
return QueryableHelper<T >.ThenBy(source, propertyName, sortDirection);
}
/// <summary >
/// 把IOrderedQueryable[T]集合继续指定属性排序方式进行排序
/// </summary >
/// <typeparam name="T" >动态类型</typeparam >
/// <param name="source" >要排序的数据集</param >
/// <param name="sortCondition" >列表属性排序条件</param >
/// <returns ></returns >
public static IOrderedQueryable<T > ThenBy<T >(this IOrderedQueryable<T > source, PropertySortCondition sortCondition)
{
PublicHelper.CheckArgument(sortCondition, "sortCondition");
return source.ThenBy(sortCondition.PropertyName, sortCondition.ListSortDirection);
}
这里使用了ListSortDirection来表示排序方向,当然,你也可以定义ThenByDescending扩展方法来进行反序排序。上面的排序可以写成如下所示:
source.OrderBy("AddDate").ThenBy("IsDeleted", ListSortDirection.Descending);
(二) 分页查询下面来说说分页查询,通常分页查询的设计方法是在仓储操作Repository中定义特定的方法来获取分页的数据,现在我们面对的是IQueryable<T >数据集,就不用那么麻烦了。只要定义一个专用于分页查询的扩展方法即可。代码如下:
/// <summary >
/// 把IOrderedQueryable[T]集合继续指定属性排序方式进行排序
/// </summary >
/// <typeparam name="T" >动态类型</typeparam >
/// <param name="source" >要排序的数据集</param >
/// <param name="sortCondition" >列表属性排序条件</param >
/// <returns ></returns >
public static IOrderedQueryable<T > ThenBy<T >(this IOrderedQueryable<T > source, PropertySortCondition sortCondition)
{
PublicHelper.CheckArgument(sortCondition, "sortCondition");
return source.ThenBy(sortCondition.PropertyName, sortCondition.ListSortDirection);
}
/// <summary >
/// 从指定 IQueryable[T]集合 中查询指定分页条件的子数据集
/// </summary >
/// <typeparam name="T" >动态类型</typeparam >
/// <param name="source" >要查询的数据集</param >
/// <param name="predicate" >查询条件谓语表达式</param >
/// <param name="pageIndex" >分页索引</param >
/// <param name="pageSize" >分页大小</param >
/// <param name="total" >输出符合条件的总记录数</param >
/// <param name="sortConditions" >排序条件集合</param >
/// <returns ></returns >
public static IQueryable<T > Where<T >(this IQueryable<T > source, Expression<Func<T, bool > > predicate, int pageIndex, int pageSize,
out int total, PropertySortCondition[] sortConditions = null) where T : Entity
{
PublicHelper.CheckArgument(source, "source");
PublicHelper.CheckArgument(predicate, "predicate");
PublicHelper.CheckArgument(pageIndex, "pageIndex");
PublicHelper.CheckArgument(pageSize, "pageSize");
total = source.Count(predicate);
if (sortConditions == null || sortConditions.Length == 0)
{
source = source.OrderBy(m = > m.AddDate);
}
else
{
int count = 0;
IOrderedQueryable<T > orderSource = null;
foreach (PropertySortCondition sortCondition in sortConditions)
{
orderSource = count == 0
? source.OrderBy(sortCondition.PropertyName, sortCondition.ListSortDirection)
: orderSource.ThenBy(sortCondition.PropertyName, sortCondition.ListSortDirection);
count++;
}
source = orderSource;
}
return source != null
? source.Where(predicate).Skip((pageIndex - 1) * pageSize).Take(pageSize)
: Enumerable.Empty<T >().AsQueryable();
}
这样,要获取某页数据,只要调用这个扩展方法即可,跟调用系统的扩展方法一样方便(其中total是总记录数)。
int total;
var pageData = source.Where(m = > m.IsDeleted, 4, 20, out total);
(三) 查询实战下面,我们来实战一下数据查询。
首先,我们要查询的数据将用下面这个类来显示,其中LoginLogCount为当前用户的登录次数,RoleNames为用户拥有的角色名称集合,这两个数据都来源于与Member有关联的其他表。
namespace GMF.Demo.Site.Models
{
public class MemberView
{
public int Id { get; set; }
public string UserName { get; set; }
public string NickName { get; set; }
public string Email { get; set; }
public bool IsDeleted { get; set; }
public DateTime AddDate { get; set; }
public int LoginLogCount { get; set; }
public IEnumerable<string > RoleNames { get; set; }
}
}
为了简化演示操作,引入分页控件MVCPager来处理页面上的分页条的处理。
Controller中代码如下,注意数据获取的查询代码:
namespace GMF.Demo.Site.Web.Controllers
{
[Export]
public class HomeController : Controller
{
[Import]
public IAccountSiteContract AccountContract { get; set; }
public ActionResult Index(int? id)
{
int pageIndex = id ?? 1;
const int pageSize = 20;
PropertySortCondition[] sortConditions = new[] { new PropertySortCondition("Id") };
int total;
var memberViews = AccountContract.Members.Where(m = > true, pageIndex, pageSize, out total, sortConditions).Select(m = > new MemberView
{
UserName = m.UserName,
NickName = m.NickName,
Email = m.Email,
IsDeleted = m.IsDeleted,
AddDate = m.AddDate,
LoginLogCount = m.LoginLogs.Count,
RoleNames = m.Roles.Select(n = > n.Name)
});
PagedList<MemberView > model = new PagedList<MemberView >(memberViews, pageIndex, pageSize, total);
return View(model);
}
}
}
这里虽然使用了MVCPager,但并没有使用她的分页功能。分页处理还是我们自己做的,只是使用了她的单页数据模型类PageList<T >作为视图模型
View代码如下:
@using Webdiyer.WebControls.Mvc;
@using GMF.Component.Tools;
@model PagedList<GMF.Demo.Site.Models.MemberView >
@{
ViewBag.Title = "Index";
Layout = "~/Views/Shared/_Layout.cshtml";
}
<h2 >Index</h2 >
@if (!User.Identity.IsAuthenticated)
{
@Html.ActionLink("登录", "Login", "Account")
}
else
{
<div >
用户 @User.Identity.Name 已登录
@Html.ActionLink("退出", "Logout", "Account")
</div >
}
<table >
<tr >
<th >UserName</th >
<th >NickName</th >
<th >Email</th >
<th >IsDeleted</th >
<th >AddDate</th >
<th >LoginLogCount</th >
<th >RoleNames</th >
</tr >
@foreach (var item in Model) {
<tr >
<td >@Html.DisplayFor(modelItem = > item.UserName)</td >
<td >@Html.DisplayFor(modelItem = > item.NickName)</td >
<td >@Html.DisplayFor(modelItem = > item.Email)</td >
<td >@Html.DisplayFor(modelItem = > item.IsDeleted)</td >
<td >@Html.DisplayFor(modelItem = > item.AddDate)</td >
<td style="text-align:center;" >
@Html.DisplayFor(modelItem = > item.LoginLogCount)
</td >
<td >@item.RoleNames.ExpandAndToString(",")</td >
</tr >
}
</table >
@Html.Pager(Model, new PagerOptions
{
PageIndexParameterName = "id"
})
显示效果如下:
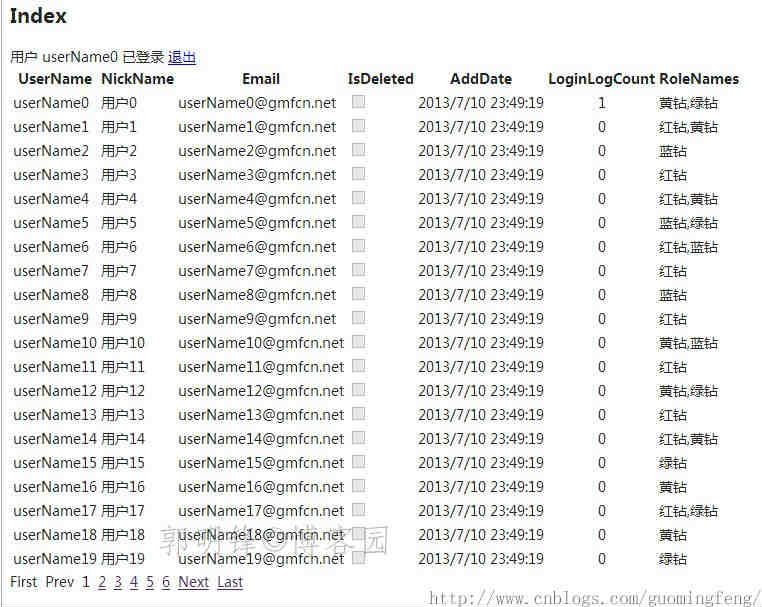
查询执行的SQL语句如下:
SELECT
[Project2].[Id] AS [Id],
[Project2].[UserName] AS [UserName],
[Project2].[NickName] AS [NickName],
[Project2].[Email] AS [Email],
[Project2].[IsDeleted] AS [IsDeleted],
[Project2].[AddDate] AS [AddDate],
[Project2].[C2] AS [C1],
[Project2].[C1] AS [C2],
[Project2].[Name] AS [Name]
FROM ( SELECT
[Limit1].[Id] AS [Id],
[Limit1].[UserName] AS [UserName],
[Limit1].[NickName] AS [NickName],
[Limit1].[Email] AS [Email],
[Limit1].[IsDeleted] AS [IsDeleted],
[Limit1].[AddDate] AS [AddDate],
[Join1].[Name] AS [Name],
CASE WHEN ([Join1].[Member_Id] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1],
[Limit1].[C1] AS [C2]
FROM (SELECT TOP (20) [Project1].[Id] AS [Id], [Project1].[UserName] AS [UserName], [Project1].[NickName] AS [NickName], [Project1].[Email] AS [Email], [Project1].[IsDeleted] AS [IsDeleted], [Project1].[AddDate] AS [AddDate], [Project1].[C1] AS [C1]
FROM ( SELECT [Project1].[Id] AS [Id], [Project1].[UserName] AS [UserName], [Project1].[NickName] AS [NickName], [Project1].[Email] AS [Email], [Project1].[IsDeleted] AS [IsDeleted], [Project1].[AddDate] AS [AddDate], [Project1].[C1] AS [C1], row_number() OVER (ORDER BY [Project1].[Id] ASC) AS [row_number]
FROM ( SELECT
[Extent1].[Id] AS [Id],
[Extent1].[UserName] AS [UserName],
[Extent1].[NickName] AS [NickName],
[Extent1].[Email] AS [Email],
[Extent1].[IsDeleted] AS [IsDeleted],
[Extent1].[AddDate] AS [AddDate],
(SELECT
COUNT(1) AS [A1]
FROM [dbo].[LoginLogs] AS [Extent2]
WHERE [Extent1].[Id] = [Extent2].[Member_Id]) AS [C1]
FROM [dbo].[Members] AS [Extent1]
) AS [Project1]
) AS [Project1]
WHERE [Project1].[row_number] > 0
ORDER BY [Project1].[Id] ASC ) AS [Limit1]
LEFT OUTER JOIN (SELECT [Extent3].[Member_Id] AS [Member_Id], [Extent4].[Name] AS [Name]
FROM [dbo].[RoleMembers] AS [Extent3]
INNER JOIN [dbo].[Roles] AS [Extent4] ON [Extent4].[Id] = [Extent3].[Role_Id] ) AS [Join1] ON [Limit1].[Id] = [Join1].[Member_Id]
) AS [Project2]
ORDER BY [Project2].[Id] ASC, [Project2].[C1] ASC
执行的SQL语句虽然比较复杂,但是确实是按我们的需求来进行最简查询的,比如我们没有查询Member的Password属性,上面就没有Password相关的语句,LoginLog的计数,Roles的Name属性的筛选,也没有涉及该类的其他属性的查询。
来源:http://www.cnblogs.com/guomingfeng/p/mvc-ef-query.html
说明:所有来源为 .net学习网的文章均为原创,如有转载,请在转载处标注本页地址,谢谢!