SQL Server的优化器对大部分人来说是非常神秘的,现在我们就来看看优化器是如何建立一个可执行的计划,以及其使用的规则。为了说明优化器执行的过程,我们将会通过逐步施加必要的规则的设置,来产生更好的执行计划。
下面是一个简单的查询(使用AdventureWorks示例数据库),显示了在数据仓库中每个产品的总数目:
SELECT P.ProductNumber,P.ProductID,total_qty = SUM(I.Quantity) FROM
Production.Product P INNER JOIN Production.ProductInventory AS I
ON I.ProductID = P.ProductID
WHERE P.ProductNumber LIKE N'T%'
GROUP BY P.ProductID,P.ProductNumber;
在SQL Server命中查询优化器前,SQL Server已经为解析和绑定查询做了一大堆工作。但当开始解析和绑定查询时,完成了一棵由逻辑关系操作符组成的树,如下:
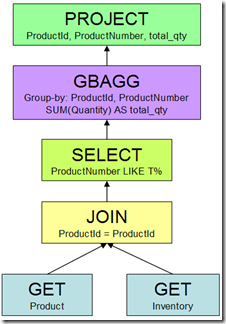
优化器需要把这棵树转化为可以被查询处理器(Query Processor)执行的计划。如果查询优化器除了转化逻辑关系运算符为它找到的第一个有效形式外,而没做其他事情,我们会得到这样的计划:
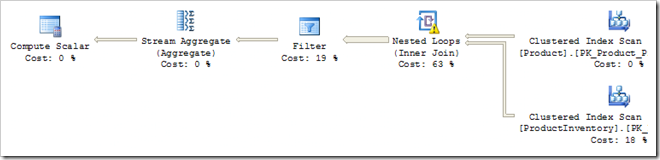
这个可执行计划有两个全表扫描(full table scan),一个笛卡尔积(Cartesian),一个在两个谓词上的过滤器(Filter),以及一个聚合(aggregate)。要产生最优的查询计划,有一个很长的路要走,但它毕竟产生正确的结果了。 (这边的Compute Scalar,是确保SUM汇总在没有行被处理时返回NULL而不是零)。
匹配和应用规则优化器通过更换逻辑运算为它所知道的对应的物理操作来生成整个执行计划。这种类型的转换是由优化器内部通过实施一系列规则来完成的。例如,逻辑运算的“INNER JOIN”,对应的物理操作则是嵌套循环(Nested Loops)(还存在merge和hash join的规则)。
上面所展示的从逻辑树到执行计划的图中,优化器共匹配和执行了5个规则:
1,GET 转化为扫描(scan)
2,Join 转化为嵌套循环(nested loop)
3,SELECT转化为过滤器(Filter)
4,Group by Aggregate 转化为 stream aggregate
5,Group by Aggregate 转化为 Hash aggregate
第一条规则取代的逻辑表扫描得到的。第二条规则实现的逻辑连接使用如前面提到的嵌套循环。第三把所有的谓词(包括联接谓词)转化为一个过滤器操作。第四和第五条规则代表了两种可供选择的策略来让物理操作层面执行聚集。在这种情况下,优化器根据成本选择了一个流聚合在一个哈希聚合。
好了,如果它产生的那种计划定期,没有人会购买SQL Server。幸运的是,还有很多其他优化器可以使用的规则,事实上有近四百种规则。不过,查询优化器产生这样一个令人沮丧的计划,是因为十多个单独的规则被关闭,我们是特意这样做的。
随着更多的规则被实施,我们会发现有许多勘探(exploration)和替代(substitution)规则。这些会基于数学等价或启发式
将逻辑请求变换成等价的形式。例如,“join Commute”是条勘探规则。这条规则的事实表明了A JOIN B等同于B JOIN A(内部联接)。
优化器同样也有简化的规则和强制的规则。通过应用所有这些规则,会产生相关替代策略,其中最好的将被纳入最后的计划。
改进计划上面的可执行计划的一个明显的不足之处是,它在的两个源表过滤器上执行了笛卡尔乘积。此时,评估联接谓词的同时进行物理连接,其实会更有效。执行此任务的规则被称为SELonJN(SELECT JOIN)。需要强调的是,这不是T-SQL SELECT语句,它是SELECT关系操作:应用于行的过滤器。使SELonJN优化规则,我们可以得到一个更好的计划:
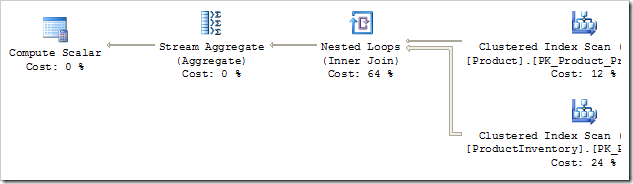
笛卡尔乘积已经换成了一个更为正常的Nested Loops运算符,这是一个将过滤器移入联接谓词的结果(去掉了filter)。事实上,过滤器运算符完全消失 – 谓词“ProductNumber LIKE’T%”没被解析吗?其实它也被往后推了 – 所有Product表扫描的由来。
这仍然不是一个好的计划:我们每一次从Product表中的找到每一行相匹配的ProductNumber谓词时,就要扫描整个Inventory表。我们需要知道非聚集索引的规则 — 简单的将一个GET转化为表扫描所依赖的基本规则。应用一些更多的规则后,我们产生如下执行计划:
这一个是好一点了,我们现在使用了正确的非聚集索引,但这个谓词被应用为扫描了 – 而不是我们希望的索引查找(index seek)。再应用一些另外的规则后,我们将会得到了一个非常有效的执行计划。
优化器已经把谓词”ProductNumber LIKE ‘T%’从一个过滤器Filter转变为在Product表上的索引扫描(index scan),但这仍然是一个遗留的谓词(索引扫描的效率还不是最高的)。我们需要使能一个新的转换规则(SelResToFilter)来让优化器重新将LIKE语句生成为索引查找(index seek):
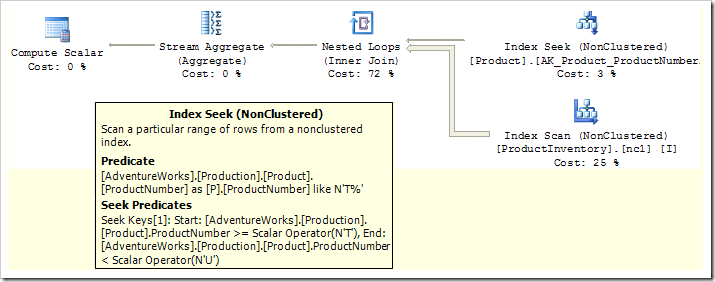
注意到,LIKE现在已经展开为一个可SARG的形式(SARG:Searchable Arguments -http://baike.baidu.com/view/587074.htm),原来的LIKE谓词现在变为从索引查找返回的行。
剩下效率不高的部分是为了匹配我们新的查找操作返回的行而对整个Inventory表索引进行的扫描。(执行计划是右上部分先被执行)。此时,在Nested Loop操作里面会执行JOIN这个谓词(匹配在两个表之间的ProductId)。如果在Inventory表的聚集索引上进行索引查找,那么我们又可以提高我们的执行效率了。
为了达成这一的目标,我们需要做两件事:
将简单的嵌套循环连接(naive nested loops join)转换为一个基于索引嵌套循环连接(index nested loops join).。(嵌套循环查询)
使用当前的Product.ProductId值来驱动每一次的Inventory表查找。
第一件事可以通过一个叫JNtoIdxLookup的规则来达成。第二个则要求一个关联的循环连接–也叫做Apply.这条规则的名称也叫做AppIdxToApp。
在优化器应用了上述两个规则(JNtoIdxLookup和AppIdxToApp)后,我们得到如下的执行计划:
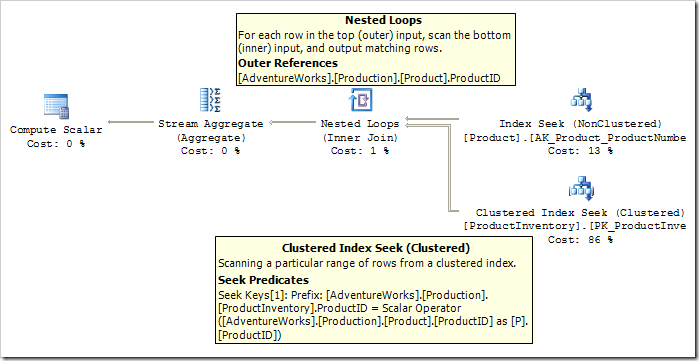
现在,我们已经离最佳的执行计划很近了。最后一步将计算标量(Compute Scalar)转化为流聚合(Stream Aggregate)。前面提到,Compute Scalar的作用是确保在没有行被处理时SUM聚合操作返回NULL而不是0.
从Compute Scalar的含义来看,这边Compute Scalar用于评估基于Stream Aggregate所产生的COUNT(*)的结果的CASE语句。我们可以移除这个计算标量(compute scalar)的动作,要计算COUNT(*),我们需要使用一个叫做NormalizeGbAgg的规则来调整GROUP BY谓词。一旦应用完该规则后,我们得到如下的最终执行计划:
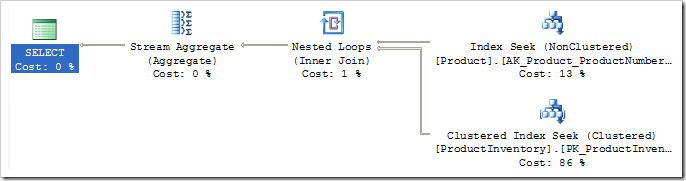
再来看下我们最初的执行计划怎样,是不是是有很大的改进?
下一步,我们将会看到如何定制可用的规则,并介绍更多的查询优化>