前言为了充分探讨查询优化器使用规则构造执行计划的方式,我们需要一个来确定用于优化特定查询的那些规则。在SQL Server 2005以后,包含了一个未公开的DMV(Dynamic Management View),该DMV会显示优化器所使用的规则。在运行一个测试的查询之前,查看下该DMV所显示信息的快照,并与运行测试查询后的DMV数据进行比较,我们可以推导出优化器为该查询所调用的规则。
在我们开始了解该DMV之前,我们需要确定几个关于SQL Server查询优化器的内幕。接下来的内容都是基于在文章1里展示的’trees 和 rules’的信息。
优化的过程查询优化是一个迭代的过程,首先从逻辑操作符树的根部开始,并以一个合适的物理操作结束。各种可能的执行计划是通过运用各种规则来生成的,这些规则会导致当前执行计划的某个部分进行一个逻辑转换或者转化为一个物理操作。
优化器并不会尝试去匹配每条查询里每一部分所有可用的规则。尽管全面匹配可以保证找到最好的执行计划,但其编译时间和内存使用却是无法接受的。
为了快速的找到一个好的执行计划,优化器会使用一系列的技巧。在后续的文章中,我们会介绍更多这方面的细节,但其中有两个技巧是直接与该DMV相关的:
每一个在逻辑树中的操作符包含代码来描述所有与它相匹配的规则。这防止优化器去尝试一些规则导致最后没有机会产生一个更低成本的执行计划。
每个规则里都包含了代码来计算出一个值,从而表示在当前上下文中规则是否是更优的。如果一个规则能够减少执行计划的总体成本(cost),那么它就更高的期望值。一般来说,常用的优化(比如改进谓词)就更具高期望值的。而更专业的规则,就像那些匹配索引视图的期望值就不会那么高了。
当面对几个可能的规则,优化器使用期望值作为部分裁剪(prune)策略。这有助于减少编译时间,但同时仍然在寻找最优的转换。
sys.dm_exec_query_transformation_stats
该DMV里每条规则对应一行,有如下几个列:
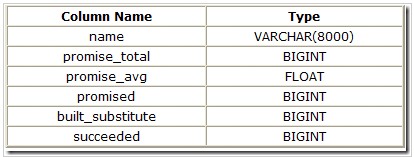
name这列表示该规则的内部名称,例如JNtoSM 表示将一个逻辑的inner join转换为物理的sort-merge join操作符。
promised 列表示该规则已经被请求为优化器提供期望值。
promise_total 列是所有期望值的一个简单求和。
promise_avg列刚好是promise_total除以promised
built_substitute列跟踪了该规则多少次产生一个备用的实现。
succeeded列跟踪了多少次该规则生成一个转换且被成功添加选为有效的备用策略。并不是所有的产生一个备用实现的转换都会匹配当前查询的执行计划的特殊要求。(例如,备用实现可能不会保存一个请求的排列顺序或者其他属性)。
使用该 DMV
下列脚本在SQL Server x86 Developer Edition, versions 10.0.2775 (2008 SP1 CU8) 和 9.0.4294 (2005 SP3 CU9)版本上已经测试通过,但也可能在其他版本上不可用。
既然该DMV包含了整个server范围的优化器信息,为了获取正确结果,你需要保证没有其他并行的优化活动正在测试的服务器上运行。最好是在一个测试的SQL Server服务器上并保证当前只有一个连接的环境上来进行测试。
首先,我们需要生产一个临时表来保存在运行测试查询前该DMV里的值的快照:
SELECT TOP (0)
name,
promise_total,
promised,
built_substitute,
succeeded
INTO #Snapshot
FROM sys.dm_exec_query_transformation_stats;
现在,我们可以写一个批处理来捕获一个该DMV的快照,然后运行我们的测试查询,接着show出运行后与运行前该DMV里值的差异:
-- Clear the snapshot
TRUNCATE TABLE #Snapshot;
-- Save a snapshot of the DMV
INSERT #Snapshot
(
name,
promise_total,
promised,
built_substitute,
succeeded
)
SELECT name,
promise_total,
promised,
built_substitute,
succeeded
FROM sys.dm_exec_query_transformation_stats
OPTION (KEEPFIXED PLAN);
-- Query under test
-- Must use OPTION (RECOMPILE)
SELECT P.ProductNumber,
P.ProductID,
total_qty = SUM(I.Quantity)
FROM Production.Product P
JOIN Production.ProductInventory I
ON I.ProductID = P.ProductID
WHERE P.ProductNumber LIKE N'T%'
GROUP BY
P.ProductID,
P.ProductNumber
OPTION (RECOMPILE);
-- Results
SELECT QTS.name,
promise = QTS.promised - S.promised,
promise_value_avg =
CASE
WHEN QTS.promised = S.promised
THEN 0
ELSE
(QTS.promise_total - S.promise_total) /
(QTS.promised - S.promised)
END,
built = QTS.built_substitute - S.built_substitute,
success = QTS.succeeded - S.succeeded
FROM #Snapshot S
JOIN sys.dm_exec_query_transformation_stats QTS
ON QTS.name = S.name
WHERE QTS.succeeded != S.succeeded
ORDER BY
promise_value_avg DESC
OPTION (KEEPFIXED PLAN);
该测试查询必须有OPTION (RECOMPILE)查询hint,确保会有一个编译发生。该批处理中的其他语句有OPTION(KEEPFIXED PLAN)来避免编译导致的结果发生偏差。
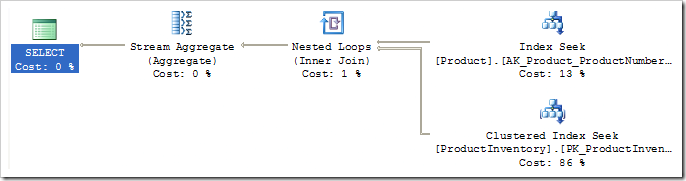
上面的例子中,使用的是我们在AdventureWorks一直运行的查询语句。它最后生成了我们前面已经看到过的,充分优化的执行计划:
下面从一个典型的运行中的(部分)结果:
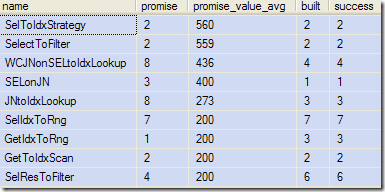
输出显示了规则名字,期望值被计算的次数,所产生的平均的期望值,转换结构被创建的次数,以及该结构被成功加入到优化器的可选列表的次数。
需要注意到的是,规则可能被调用多次,因为它们可能在查询语句里的多个地方被匹配,同时编译过程是一个递归过程。同时,我们也注意到有些规则的期望值为0,这意味着计算期望值的代码没有足够的信息来生成值。